Using Word2Vec and t-SNE to Plot Word Similarity in Shakespearean Plays
It is understood that there are significant distinctions between the stylistic makeup Shakespearean tragedies and comedies. Tragedies typlically have a cental flawed figure, and the general sentiment of tragedies ebb and flow according to the machinations of that central figure.
Comedies on the other hand, have multiple varied plot lines and, using NLP verbage, will have more disparate topicality. I was hoping Word2Vec could echo my undrstanding of tragedies and comedies when plotting word relationships in space. Word2Vec will use either a SkipGram model or a CBOW to derive realtive distances between words. A Skipgram model will find context words given a single word, while a CBOW module does the opposite. It then creates word vectors with pre-defined dimensions based on those word associations.
In order to use Word2Vec, I had to create corpora of individual documents (sentences). Each document is arranged as a list, with each word sitting as an element within that list. I first filtered out both stopwords and names of characters that denote the speaker at the time. I then ran my model through Word2Vec and plotted my results using T-SNE. T-SNE uses a version of singular value decomposition (SVD) to reduce the dimensionality of my word vectors to two, so that we could visualize them with ease.
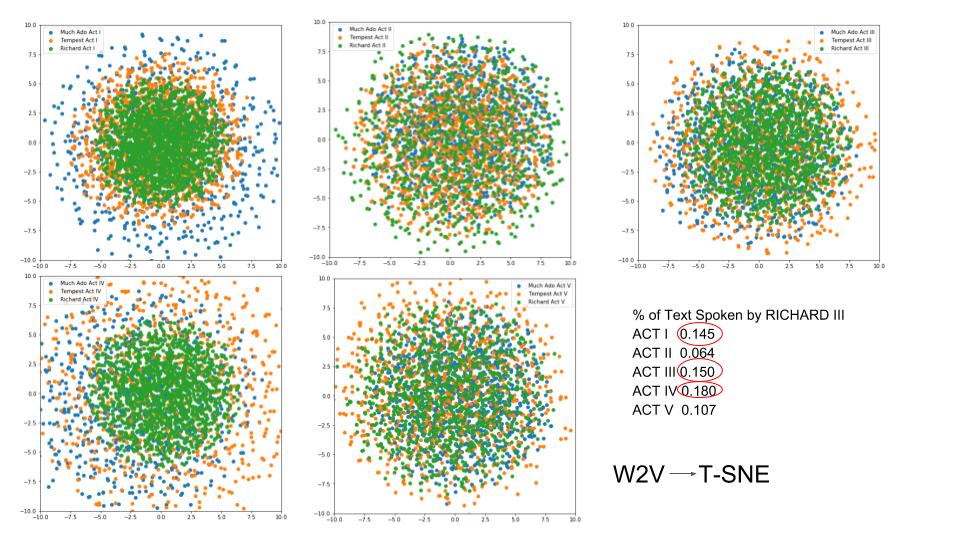
I plotted the tragedy Richard III relative to two comedies (The Tempest and Much Ado About Nothing), and we see that the tragedy (in green) has a much stronger gravitational center than the two comedies.
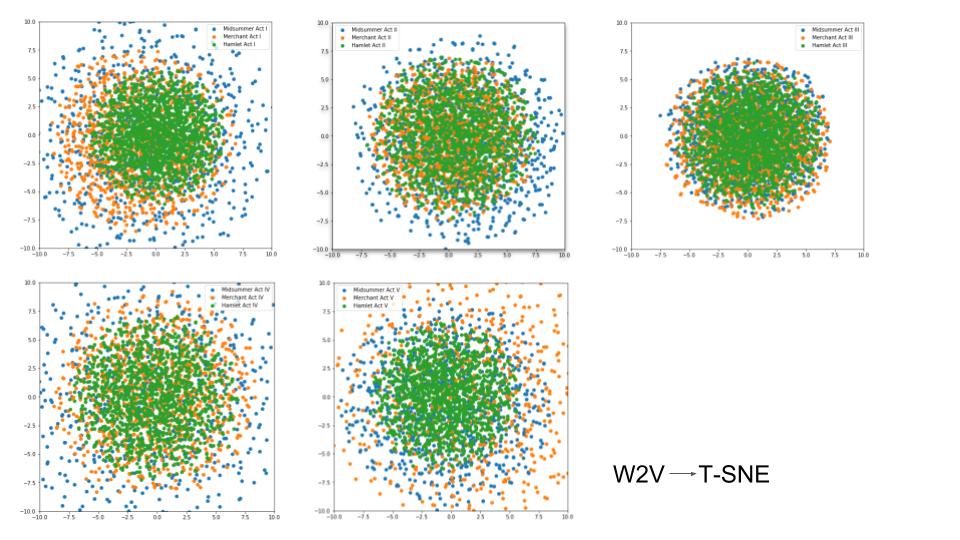
I then plotted Hamlet (also a tragedy) relative to two different comedies (A Midsummer Night’s Dream and The Merchant of Venice). I was able to see the same results where, on average, the words for the tragedy were closer in space than those for the comedies.